
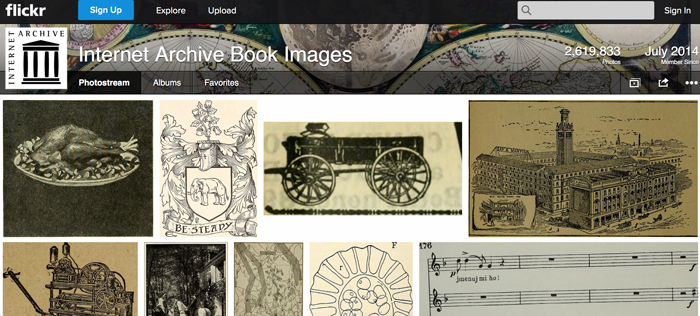







L’organisation Internet Archive et un universitaire américain ambitionnent de créer sur Flickr une base de données ouverte de 14 millions d’images historiques libres de droits. Kalev Leetaru y a déjà téléchargé 2,6 millions de photos, consultables grâce à des balises ajoutées.
Ces photos, dessins et croquis, issus de livres remontant pour certains à plusieurs siècles, proviennent de plus de 600 millions de pages de livres de bibliothèque numérisés par l’organisation Internet Archive. Déjà connue pour permettre le téléchargement gratuit (et légal) de centaines de milliers de films, de concerts, de livres numériques ou bien encore d’émissions de radio, mais également de pages web (depuis 1996, l’association en a archivé près de 400 milliards qu’elle met gratuitement à disposition des internautes sur un site dédié). En annonçant ce projet le 29 août 2014, l’association américaine Internet Archive continue ainsi d’œuvrer en faveur d’une large diffusion de la culture.
Kalev Leetaru a déclaré à la BBC: “Les projets de numérisation ont jusqu’à présent été concentré sur les mots et les images ont été largement ignorées. Ils ont mis l’accent sur les livres comme une collection de mots. Pendant toutes ces années toutes les bibliothèques ont numérisé leurs livres, mais ces numérisations étaient disponibles sous forme de PDF. Les images étaient difficiles d’accès jusqu’à présent. Mon projet inverse cela et remet la photo en première ligne. La base de données portant sur une demi millénaire permet au public de découvrir un éventail complet d’images et de comprendre comment les représentations de choses ont changé au fil du temps.”
14 à 16 millions d’images de 1500 à 1922
Internet Archive et l’initiateur du projet ambitionnent d’intégrer sur Flickr 14 millions d’images. Sur les 14 millions d’images déjà extraites et numérisées, 2,6 millions ont déjà été téléchargées sur Flickr Commons. Bientôt, la base de données pourra s’enrichir des extractions d’images provenant des plus de 1000 nouveaux livres numérisés chaque jour par l’organisation.
Selon Kalev Leetaru, «la plupart des images qui sont dans les livres ne sont pas présentées dans des galeries d’art ou musée du monde et les originaux ont depuis longtemps été perdus.”
“Ces 14 millions d’images de haute résolution couvriront tous les sujets imaginables, musique, sciences et techniques, atlas, histoire…” annonce l’association.
Les images datent de 1500 à 1922, lorsque des restrictions de droits d’auteur limitent le projet. Diffusées sur Flickr et supposées tombées dans le domaine public, les photos peuvent être copiées et téléchargées librement par les visiteurs du site. Chaque photo est accompagnée de la mention “Aucune restriction de droit d’auteur connue”.
Ouverte à chacun, cette base d’images devrait s’avérer utile pour les historiens, qu’ils soient amateurs ou professionnels.

Soutien indirect de Yahoo
Kalev Leetaru a commencé à travailler sur le projet, lorsqu’il étudiait les technologies de la communication à l’Université de Georgetown à Washington DC, dans le cadre d’une bourse parrainée par Yahoo, le propriétaire du service de partage de photos Flickr.
Le projet ne consiste pas seulement à agréger des images mais également à permettre leur recontextualisation et donc meilleure compréhension. Les images mises en ligne sur Flickr sont accompagnées de métadonnées qui permettent de les expliquer (titre du livre, auteur, année de publication, éditeur, légende, mots-clé de description…). Chaque photo est également associée aux 500 mots précédant et succédant chaque image sur le livre d’origine. Ces extraits de texte peuvent être consultés directement depuis la page Flickr de l’image, à partir de laquelle il est également possible d’accéder au livre d’origine, en version numérisée.
Pour atteindre son objectif, Kalev Leetaru a développé son propre logiciel afin de pouvoir puiser plus facilement dans la base de données de l’Internet Archive constituée de 2 millions de livres et de 600 millions de pages numérisées et en extraire quasi automatiquement les photographies en format Jpeg. Ce logiciel permet également de “raccrocher” chaque photo extraite à sa page et à son texte d’origine pour le recontextualiser. Ainsi le logiciel a copié la légende de chaque image et le texte des paragraphes précédents et suivants dans le livre.
Chaque image en Jpeg et son texte associé a ensuite été intégré sur la plateforme Flickr sous la forme d’une page, et le moteur de recherche du site permet au public de naviguer dans le vaste catalogue.
«Les visiteur de Flickr vont ainsi pouvoir faire un Voyage dans le temps à travers les images», a déclaré M. Leetaru.
Se rapprocher de Wikipédia
Internet Archive et Kalev Leetaru ne souhaitent pas s’arrêter là.
Robert Miller, directeur du livre pour Internet Archive envisage “plus d’images, plus de sous-collections et des idées très intéressantes sur la façon d’utiliser ces images comme certains outils de reconnaissance d’images”.
Une fois l’intégration des photos terminées en 2015, le chercheur rêve d’un rapprochement avec la plus célèbre encyclopédie de l’Internet, Wikipedia. Il se dit également prêt à “offrir” son logiciel à d’autres bibliothèques et détenteurs de collections.
Comme l’explique K Leetaru: “toute bibliothèque pourrait répéter ce processus. Mon espoir serait que les bibliothèques du monde entier utilisent ce même processus pour leurs propres livres numérisés et contribuent ainsi à élargir cet univers d’images.”

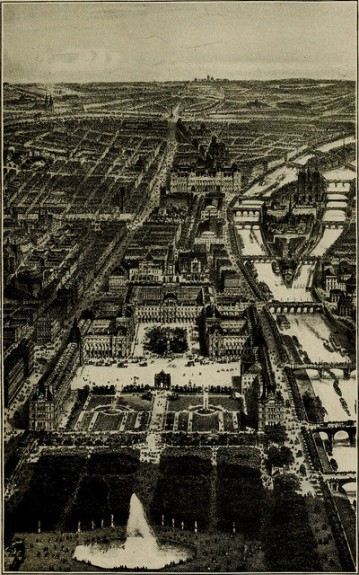

La France est déjà largement présente parmi les 2 619 300 images déjà intégrées. Avec notamment des images d’herbiers, de villes ou de personnages, des illustrations médiévales ou médicales.
SOURCES: Internet Archive, BBC
Date de première publication: 02/09/2014
![]()
. En mettant en ligne ses archives photos, le Museum de NY raconte son histoire et celle du Monde
. Wikimedia s’enrichit de 50 000 photos de la Librairie du Queensland
. La British Library met en ligne sur Flickr plus d’un million d’illustrations libres de droit
. Le Museum de Toulouse diffuse ses photos sur Wikipédia

















